Integrate Into Your Platform
Before you stage a service at-scale, implement against any APIs, or consume any of the output streams, it's helpful to understand why the product was designed the way it was, and how you will get the most value from it.
Tranquil Data Product Editions#
The Tranquil DataTM Enterprise Edition is the core engine that builds and maintains a contextual graph, implements a policy engine, defines data model abstractions for evaluation and redaction, and writes and caches pre-computed context for high-throughput, low latency decision-making. It exposes APIs for both operation and evaluation, and implements standard database protocols to act as an on-the-wire intermediary. It exposes the decision trace and change data capture streams. It provides the security framework used to integrate with popular security services. It is grounded on a distributed ledger that ensures integrity, and uses security standards to define identity and ensure confidentiality.
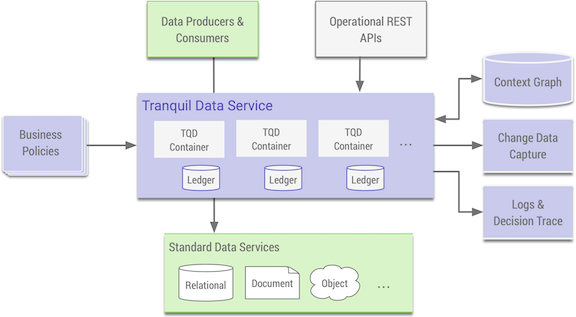
Built on top of this engine is The Tranquil DataTM Trusted Flow Edition, which is focused on common, critical touch-points and workflows. It defines policies and data models that support these flows, and hides the open-ended APIs of the engine in-favor of APIs streamlined for common platform requirments. It exports the configuration UI covered in the previous section abd extends core record redaction capabilities to documents. This is the edition that you are working with today.
Product Touch-Points#
The Tranquil DataTM Trusted Flow Edition has four key touch-points:
- The User Interface that gives Legal and Privacy teams ownership of a complete and enforcable definition of compliant data use and sharing
- The APIs that simplify user-onboarding, keep users current with terms, and unlock fine-grained consent
- The UIs, APIs, and Protocol Implementations that automate and enforce data use and sharing across an organization
- The streams that provide transparent proof of exactly how and why data was used and shared
These touch-points are deigned to scale independently. For instance, Once the product has been integrated into your platform, lawyers are free to evolve their definitions without impacting anything in code or pipelines that rely on Tranquil Data to make decisions and/or enforce actions. Similarly, teams that are working with the output streams can iterate on the value they surface, and build new capabilities over time, without needing to coordinate with privacy teams. Any new applications that are user-focused can onboard users correctly without needing to know how platform terms are evolving.
The separation of both UI and API components is with these groups in mind. This is also the typical ordering when adopting the product. Legal teams will start by defining a handful of pressing rules, use that as a starting-point to instrument one path for user-onboarding, and finally use the document redaction UI or the decision API in one part of the organization. In practice, this pattern means that within a week most teams are already surfacing value from the product, and can start to scale-out use as business requirements dictate. In each of these cases, the key is incremental adoption: Tranquil Data has been designed to give you value with only a few flows or contracts mapped. You get to decide where to start, and over time, how to bring more of your platform into Tranquil Data.
User Onboarding#
For item 2 above, the user API documentation explains several common patterns. Since most aspects of configuration are personal, the typical starting-point for any integration is via these APIs, whether you're onboarding first-party users or tracking third-parties and their data.
In the spirit of incremental adoption, however, this doesn't mean that you need to make Tranquil Data a part of your production onboarding process from the start. While you will get the most value from using the product to display personalized terms to onboarding users in an interactive flow, it's fine to start by simply calling-out to the APIs after someone has already onboarded. In practice, unless you're building a completely new offering with Tranquil Data at the core, you'll be doing some version of this to get existing users into the system.
Enforcement#
For item 3 above, there are several ways that Tranquil Data can automate and enforce that data is used and shared correctly, and to ensure that decisions are audited and captured in-context. These are explained in more detail in separate sections, but it's worth understanding your options before proceeding.
The simplest instrumentation option is the decision API, a single call that takes a single record. This is lightweight, flexible, data store/format-agnositc, and simple to implement in a number of common application and data flow patterns. It can be used as an enforcement-point, as a call-aside to validate tasks, or as a co-pilot to help developers and data scientists understand the rules of the platform. This is a common starting-point for any techology teams that want to get running quckly.
Building on that pattern, the UI and API for document redaction takes a structured document and returns a field-level redacted version valid for the stated purpose. Because the call is asyncronous it works for testing small documents and scaling to milions of records in-production, and supports running jobs in parallel. For business teams like Advertising, Marketing, or Account Management that work regularly with CSVs and similar files, the UI provides another common place to get started without any instrumentation. For tech teams building exchange APIs, this can be a great way to ensure and prove that any outgoing exchange meets requirements.
Finally, enforcement can be done at the wire-protocol level of a datastore. Tranquil Data supports exported access to a variety of datastores, where all operations flow through the service and trigger policy evaluation and context formation. This is by far the most powerful and flexible model for enforcement. It also requires changes (in-production) to infrastructure deployment, so the best starting-point is typically in a CI environment where Tranquil Data is acting as another validation component of your testing process.
Next Steps#
Now that you have the product running, and have some direction about where to begin, you should either read the operation section (if you want to learn more about staging and deploying the product), work through the API examples (if you want to learn more about instrumentation), or skip right to the datastore section to learn more about exported access.